
💡 해당 포스팅은 기본 개념과 땡칠님과 멍토님의 테코톡 영상을 바탕으로 포스팅 되는 글입니다.
기본적인 개념 + SSE에서 WebFlux를 사용할 때의 주의점을 다룹니다.

이번 포스팅에서는 늘 개발을 하며, 마주치는 용어인 동기와 비동기 그리고 블로킹과 논블로킹에 대해서 다룬다.
상위개념이 흔들릴수록 부가적인 개념도 약해지기에 확고하게 잡으려고한다.
그리고 추가적으로 이번 SSE를 쓰며, Spring 공식 스펙상에서 지원하는 타입이 SseEmitter와 WebFlux가 존재하였고 필자는 WebFlux를 적용하게 되어 그 이유를 앞선 개념들과 엮어 설명하려한다.
우선, 해당 개념들에 공통적으로 사용되는 용어가 있다.
바로 제어권과 결과값의 반환이다. 이 용어의 개념의 이해는 전체적인 연관성을 파악하기 필요하다.
💡 용어 개념
제어권
제어권이란 함수에 대한 실행 요청이 들어왔을 때 해당 코드를 실행할 권리이다.
제어권을 가진 함수는 자신의 코드를 모두 실행시키고 자신을 호출한 곳에 다시 권한을 반환한다
결과값의 반환
A 함수에서 B 함수를 호출했을 때, A 함수가 B 함수의 결과값을 기다리느냐의 여부
또한 [동기, 비동기,블로킹,논블로킹] 개념에서 공통적으로 이루고자하는 궁극의 목표가 존재한다.
그것은 바로 CPU의 성능향상이다. CPU는 소모되는 자원인가? 그렇지않다. 하지만 용량이 정해져있는 자원이다.
그렇다면, CPU를 효율적으로 사용하기 위해선 어떻게 해야하는가? 같은 작업내에서도 최대한 많이 사용하는 것이 성능향상에 기대를 걸 수 있을것이다.
Blocking vs Non-Blocking
블로킹과 논블로킹의 개념 차이는 제어권의 차이에서 발생한다.
가장 중요한 부분 중 하나가 제어권을 가져가는 입장인지, 부여받는 입장인지이다.
제어권의 주인이 제어권을 빼앗기는 입장이라면 블로킹이고, 제어권을 부여하는 입장이라면 논블로킹이다.
Blocking

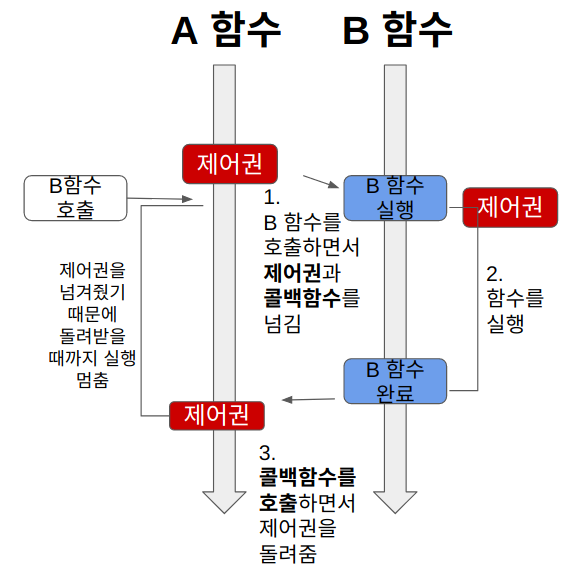
위 그림과 같이 최초실행된 A 함수에서 B 함수를 호출하는 작업이 발생한다고 가정해보자.
블로킹(Blocking)에서는 호출당한 함수가 자신의 코드를 전부 실행 시킨 후 다시 제어권을 돌려준다.
순서대로 정리해보자면 아래와 같다.
- A함수에서 B함수를 호출할 때 B에게 제어권을 넘겨준다.
- 제어권을 받은 B는 자신의 코드를 실행시키고 만약, 그 속에서도 다른 함수를 호출한다면 제어권을 넘겨준 후 실행이 끝나면 돌려받는다.
- 이때 A는 자신의 제어권을 전달한 상태이기에 코드의 실행을 잠시 멈춘다.
- B함수는 실행이 끝나면 자신을 호출한 A에게 제어권을 돌려준다
Non-Blocking
논블로킹(Non-Blocking)은 A함수가 B함수를 호출해도 제어권은 그대로 자신이 가지고 있는다.
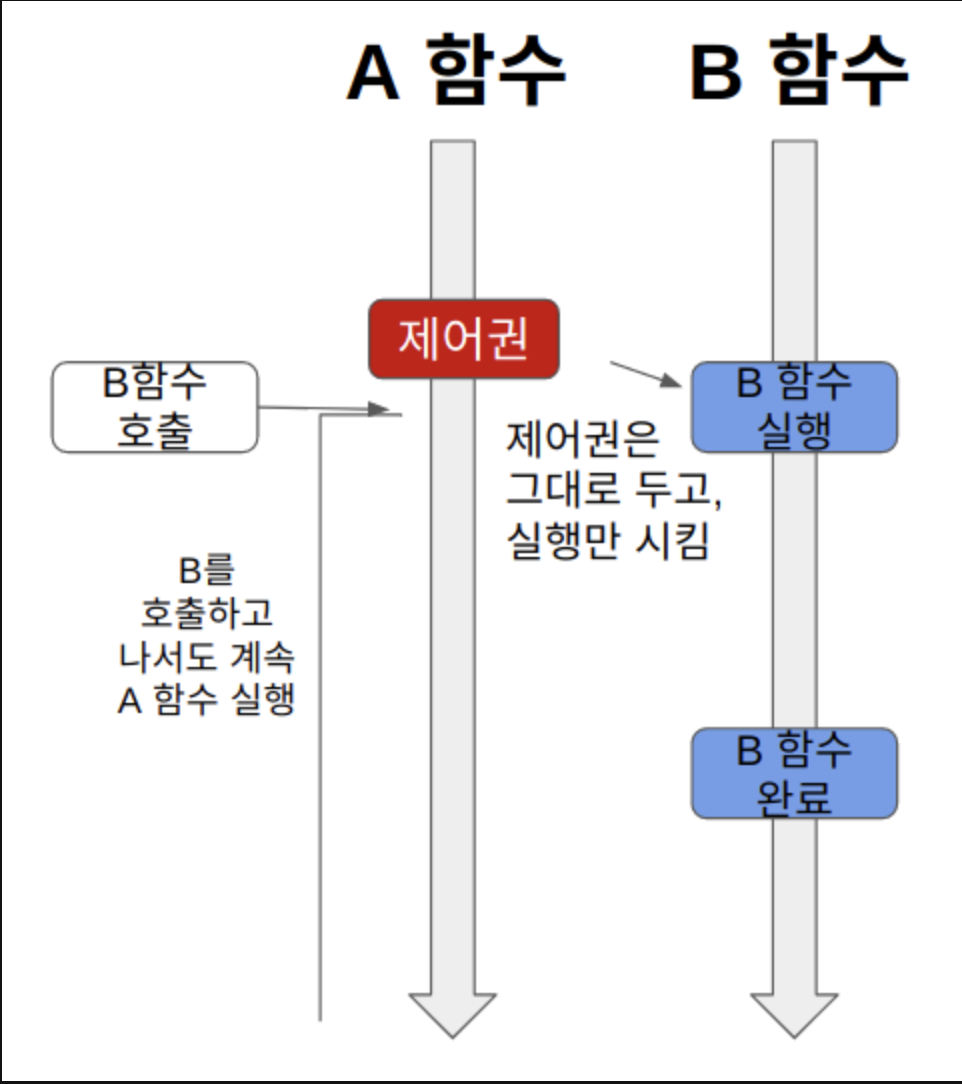
- A함수가 B함수를 호출하면, B 함수는 실행되지만, 제어권은 A 함수가 그대로 가지고 있는다.
- A함수는 계속 제어권을 가지고 있기 때문에 B함수를 호출한 이후에도 자신의 코드를 계속 실행한다.
Synchronous(동기) vs ASynchronous(비동기)
동기와 비동기의 차이는 호출되는 함수의 작업 완료 여부를 신경쓰는지의 여부이다.
한마디로 작업의 시작 / 종료 시점을 통해 제어를 하느냐 안하느냐의 차이이다.
비동기의 경우 시작 / 종료 시점에 구애 받지 않는 로직을 작성하기 위해 사용하고, 동기의 경우 반대로 순차적 실행을 위해 사용된다.
Synchronous
함수 A가 함수 B를 호출한 뒤, 함수 B의 반환 값을 대기하며 체크하는 것이 특징
ASynchronous
함수 A가 함수 B를 호출 할 때 콜백 함수를 함께 전달하여 함수 B의 코드 실행이 완료되면 콜백함수를 실행
결과적으로 동기와 달리 반환값의 상태는 영향을 끼치지 않음
종합비교
여기서 대부분의 개발자들이 동기와 블로킹의 개념을 혼동한다.
정확히는 다르지만, 얼추 비슷한 부분이 있기 때문이다.
하지만 이는 혼합될 수 있는 개념이지 같은 개념이 아니기에 각 개념들을 혼합한 상황을 살펴보자
Sync-Blocking
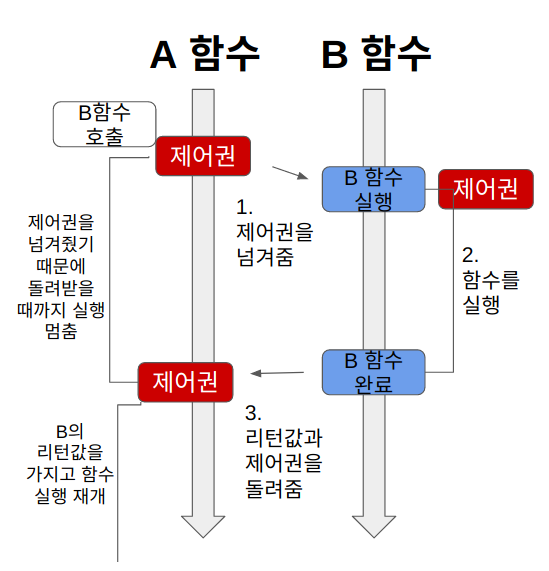
- 함수 A는 함수 B의 반환 값을 필요로한다.(동기)
- 그래서 제어권을 함수 B에게 넘겨주고, 함수 B가 실행을 완료하여 리턴값과 제어권을 돌려줄때까지 기다린다(블로킹)
Sync-Nonblocking
논블로킹과 동기 즉, 각각의 함수는 별도로 실행이 되는 상태이지만 A함수에서는 B함수의 작업이 종료되었는지 계속해서 확인하는 작업을 수행한다.
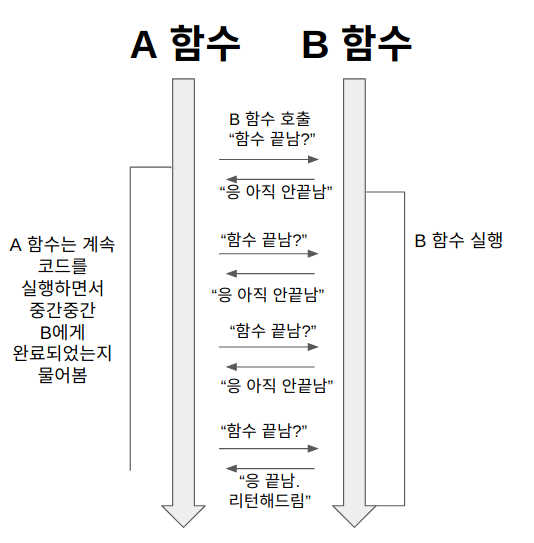
- B함수를 호출하고 자신의 함수는 계속해서 수행한다.(논블로킹)
- A함수는 B의 반환값이 필요하기에 계속해서 캐치를 시도(동기)
웹 소켓에서 이를 폴링(Polling) 방식이라고 칭한다.
해당방법은 기본적으로 상당히 리소스를 많이 잡아먹게된다.
외에도 A함수가 먼저 실행이 종료돠어도 B함수의 결과가 반환될 때까지 기다려야한다는 점에서 효율성이 좋지 못하고 이로 인한 서버 부하 또한 고려사항이다.
Async-NonBlocking
비동기 + 논블로킹은 상당히 간단하다.
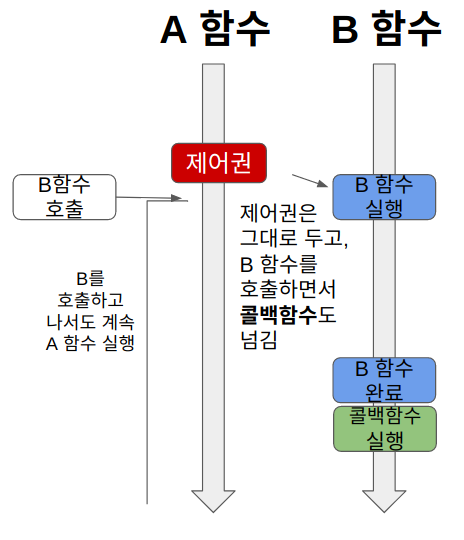
- 자신의 제어권을 넘기지 않고 B함수를 실행시킴과 동시에 콜백함수를 B함수에게 전달한다.(논블로킹)
- B함수는 자신의 코드 수행이 끝난후 콜백함수를 실행한다.(비동기)
Async-Blocking
잘 발생하지 않는 구조이며, 논리적으로도 부합하지 않는구조이다.
기본적으로 동기와 블로킹의 경우 B함수의 의존적 또는 관계적인 성향이다.
하지만 이를 비동기와 함께 사용한다? 이는 조금 어불성설적인 구조이다.
- A함수는 B함수의 실행결과(반환 값)와 상관없이 콜백함수를 전달한다.(비동기)
- 하지만 B함수의 반환 값을 실행쓰지 않는 것과 달리 제어권을 B함수에게 넘긴다(블로킹)
🧐 그래서 뭐가 좋은 구조인가요?
이런 질문에 항상 뻔한 대답 중 하나인 내 답은 정답은 없다이다.
예를 들어, 논블로킹 + 비동기 구조는 항상 좋은구조인가? 지표가 시간대비 처리량을 기준으로 한다면 그럴 수 있다.
보통, 대용량의 데이터를 서버에서 처리하기 위해 논블로킹 + 비동기를 사용한다.
하지만, 블로킹 + 동기를 멀티쓰레드로 구현한다면? 비슷한 성능을 낼 수 있다. 물론 쓰레드에게 부여되는 별도의 관리비용과 오버헤드라는 단점이 있지만 반대로, 단건처리나 작업의 순서가 보장되어야하는 작업의 경우 블로킹 + 동기 방식이 더 강점을 가지게된다.
그리고 하나의 논점이 더 존재하는데, 과연 개발자에게 성능만 비용(cost)으로 정의 할 수 있는가이다.
기본적으로 개발자의 인지 비용(코드 가독성,직관성) 또한 비용(cost)에 포함이 되어야한다.
그렇기에 자신이 구축하고자하는 서비스에 부합하는 무조건적인 정답은 없고 효율성을 높일 수 있는 구조에 대해 고려해야한다는 것이다.
하지만, 앞선 설명처럼 비효율적인 구조는 명확히 존재한다. 비동기 + 블로킹 방식의 구조는 실제로 잘쓰이지 않는 구조이며, 지금 설명할 SseEmitter와도 연관이있다.
SSE?
SSE(Server-Sent-Event)에 대해서는 별도로 다룰 예정이기에 간략하게만 설명한다면, 클라이언트 - 서버간의 Connection을 맺어, Server에서 Event를 발행하는 단방향 통신 프로토콜이다.
이러한 SSE에서 공식지원하는 타입으로는 SseEmitter와 Mono/Flux 타입이 존재한다.
필자는 이번에 SSE를 이용한 서비스 로직을 구성할 때 Flux로 반환하는 방법을 택했다.
그 이유는 SseEmitter의 특징 때문이다.
핵심만 말하자면, SseEmitter는 비동기 + 블로킹 방식으로 동작한다.
그렇기 때문에 실시간 단방향 통신을 지향하는 프로토콜이 요청당 쓰레드를 하나씩 이용하게 되어, 다수의 클라이언트가 연결된 경우에는 리소스를 많이 낭비하여, 오버헤드가 발생할 수도 있다. 그리고 최종적으로는 동시성이 중요한 서비스에서 동시성이 떨어지게 된다.
리소스를 많이 낭비하게 되는 이유는 많은 클라이언트가 동시에 연결되어 있는 상황에서 많은 수의 스레드가 생성되어 서버의 리소스를 과도하게 사용하게 되고, 이는 스레드의 생성 및 소멸, 스케줄링 오버헤드 등으로 인해 서버의 처리량을 저하 시키는 원인이된다. 또한, 스레드가 블로킹 상태에 있을 경우 해당 스레드는 다른 요청을 처리할 수 없으므로 동시성이 떨어지게된다.
마지막 줄이 가장 핵심이다. 실시간 성을 보장해야하는데 비동기 + 블로킹 구조이기에 동시성이 떨어지게된다.
비동기 속에 동기
또한 기본적으로 SseEmitter는 비동기 처리를 기반으로 한다.
그렇다면 로직 Flow가 동기 속에 비동기를 추구해야할 것이다.
여기서 말하는 동기란 기본적인 Data JPA(ORM)를 사용하여 처리하는 로직을 뜻하고, 비동기는 SSE 작업을 얘기한다.
만약, 비동기 즉 ,SSE 빌더 작업 내부에 동기 작업이 포함되어 있다면, 해당 작업이 블로킹되어 비동기적인 특성을 상실하게되어 이점을 잃어버린다.
예를 들어, SseEmitter로 클라이언트에게 데이터를 전달하는 동안 Data JPA를 사용하여 DB에서 데이터를 조회하는 경우를 생각해보자.
이때 Data JPA는 동기적인 작업으로 DB와 통신하며, 데이터 조회가 끝날 때까지 SseEmitter는 블로킹된다. 이렇게 되면 비동기적으로 다른 요청을 처리할 수 없게 되므로 효율성이 떨어지는 구조이다.
그렇기에 WebFlux를 사용한다.
비동기 Data JPA
WebFlux를 사용할 때, R2DBC를 이용하면 조회 작업 또한 비동기로 처리하여 SseEmitter보다 효율적인 구조를 사용할 수 있다.
결론
정말 개발을 하다보면, 여러 구조의 프레임워크나 라이브러리를 다뤄야할 때가 많고, 해당 구조를 옳바르게 사용하기 위해선 설계된 구조에 맞추어 코드를 작성하는 것이 옳바르게 사용하는 법이라고 생각한다.
하지만, 가끔씩 해당 개념들이 흔들리다 보면 비효율적인 코드 구조를 설계하기도 하기에 이러한 개념은 견고하게 붙잡아야겠다.
'Spring-boot' 카테고리의 다른 글
| [JPA] JPARepository vs Repository (0) | 2023.12.14 |
|---|---|
| [Spring] JDBCTemplate을 이용한 벌크연산 최적화하기 (0) | 2023.10.13 |
| [JPA] Data JPA에서 Projection 활용기 (0) | 2023.06.28 |
| [JPA] @Transaction 읽기 전용 (0) | 2023.03.29 |
| OSIV(Open-Session-In-View) 사용 (0) | 2023.03.16 |